淘宝推荐系统目前遇到的挑战
- 扩展性——数据集规模大
- 稀疏性——用户交互行为少
- 冷启动——新上线
item无用户历史交互行为
推荐一般有两个阶段:matching & ranking。 本文聚焦在matching阶段,其核心任务是基于用户行为计算所有物品的两两相似度。
对于用户交互行为稀疏的item,学习到准确的embedding向量是很难的事情。所以作者利用side information去enhance the embedding procedure。
那么什么是item的side information?可以简单的理解为item的属性,与用户行为无关。例如品牌、类别、价格等等信息。至此我们可以看到,作者认为side information相近的item 在embedding空间也应该相近。
但是,淘宝商品的side information有上百种,其中哪些side information对embedding重要的?作者设计了权重机制,应用在embedding的训练中。
下面我们来看看如何获得item embedding以及如何将side information融入到item embedding中。
作者利用用户行为进行item graph。用户行为指的是用户历史行为序列,作者利用了历史一小时内的用户行为数据进行训练。原因有以下两点:1.空间和时间限制 2.用户兴趣会随时间变化。在构建图之前,需要对数据进行消噪。可以通过以下几方面进行:
- 点击后停留时间小于1s
- 过滤异常用户。如果一个用户在三个月内点击超过3500次或者购买物品超过1000次,则认为该用户为异常用户,过滤其所有用户
- 商家更新商品描述信息太快,导致过了一段时间后同一个identifier对应的item变成了完全不一样的东西
构图过程:
1.作者构建的是有向图,每条边的权重等于由到转移次数除以整个图的转移次数。
2.只用同一session中的序列数据进行构建
Base Graph Embedding
作者首先定义了节点之间的转移概率:
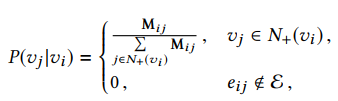
然后基于这个转移概率生成随机游走序列。
后面的过程与基于negative sampling的skip-gram一致。
Graph Embedding with Side Information
加入side information主要是减轻冷启动问题。
那么side information是如何加入的呢?通过加入一个embedding层,为item本身以及n个side information训练个embedding向量,最后进行average pooling作为输入进行训练。
网络结构如下:
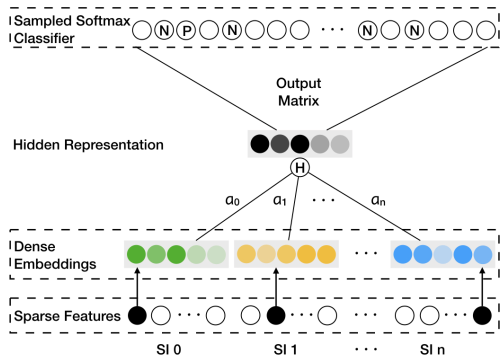
Enhanced Graph Embedding with Side Information
框架与上图一样,只是对每个side information增加了一个分数,最后采用加权池化